전체 코드
GitHub – bezkwag/casestudy
GitHub에서 계정을 생성하여 bezkwag/casestudy 개발에 기여하십시오.
github.com
분석 목적:
1. 상가 현황 파악
2. 기간별로 나타나는 카테고리 검토
3. 사용자 클러스터 분석
데이터: 파키스탄 전자상거래 데이터 세트
2016년 3월부터 2018년 8월까지 파키스탄의 전자상거래 기록이 포함되어 있습니다.
https://www.kaggle.com/datasets/zusmani/pakistans-largest-ecommerce-dataset
1. 데이터 확인
df.columns
Index(('item_id', 'status', 'created_at', 'sku', 'price', 'qty_ordered',
'grand_total', 'increment_id', 'category_name_1',
'sales_commission_code', 'discount_amount', 'payment_method',
'Working Date', 'BI Status', ' MV ', 'Year', 'Month', 'Customer Since',
'M-Y', 'FY', 'Customer ID', 'Unnamed: 21', 'Unnamed: 22', 'Unnamed: 23',
'Unnamed: 24', 'Unnamed: 25'),
dtype="object")df.shape
(1048575, 26)약 100만 행의 데이터와 26개의 행이 있습니다.
| 품목 식별 번호 | 품목 식별 번호 | 211131 | 근무 날짜 | 2016년 7월 1일 | |
| 상태 | 결제 관련 상태(15개 정도) | 완벽한 | BI 상태 | 거친 | |
| 만든 | 주문 날짜 | 2016년 7월 1일 | MV | ||
| 제품 번호 | 제품 식별 코드(80,000) | 창조물__YI06-L | 이후 고객 | 구독 기간 | 2016-7년 |
| 가격 | 가격 | 1950년 | 고객 번호 | 하나 | |
| 주문 수량 | 주문 수량 | 하나 | GJ | FY17 | |
| 총 | 총 가격 | 1950년 | |||
| category_name_1 | 범주 | 여성 패션 | |||
| 할인 량 | 인하 된 가격 | 300 | |||
| 지불 방법 | 결제수단(20) | 대구 |
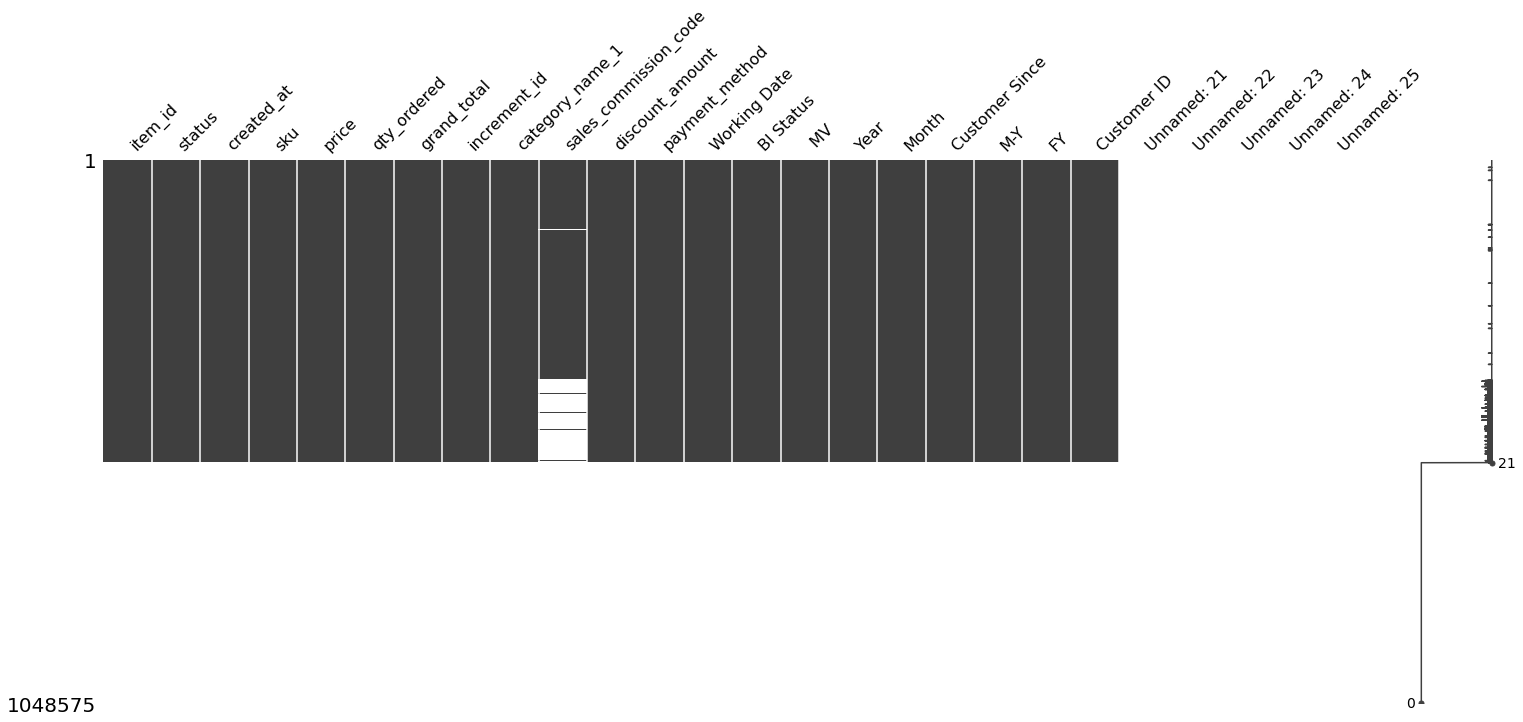
아래 흰색 데이터는 null 값입니다. 왜 이렇게 잘못된 데이터가 있는지 모르겠습니다. 그래서 뒷자료를 좀 잘라서 써야할 것 같아요. 그리고 이 열도 사용할 수 있는 항목을 필터링해야 하는 것 같습니다.
데이터가 정제되었습니다.
df1=df(('item_id','status','created_at','sku','price','qty_ordered','grand_total',
'increment_id','category_name_1','discount_amount','payment_method',
'Working Date','Customer Since','Customer ID'))
df1.shape
(584524, 14)
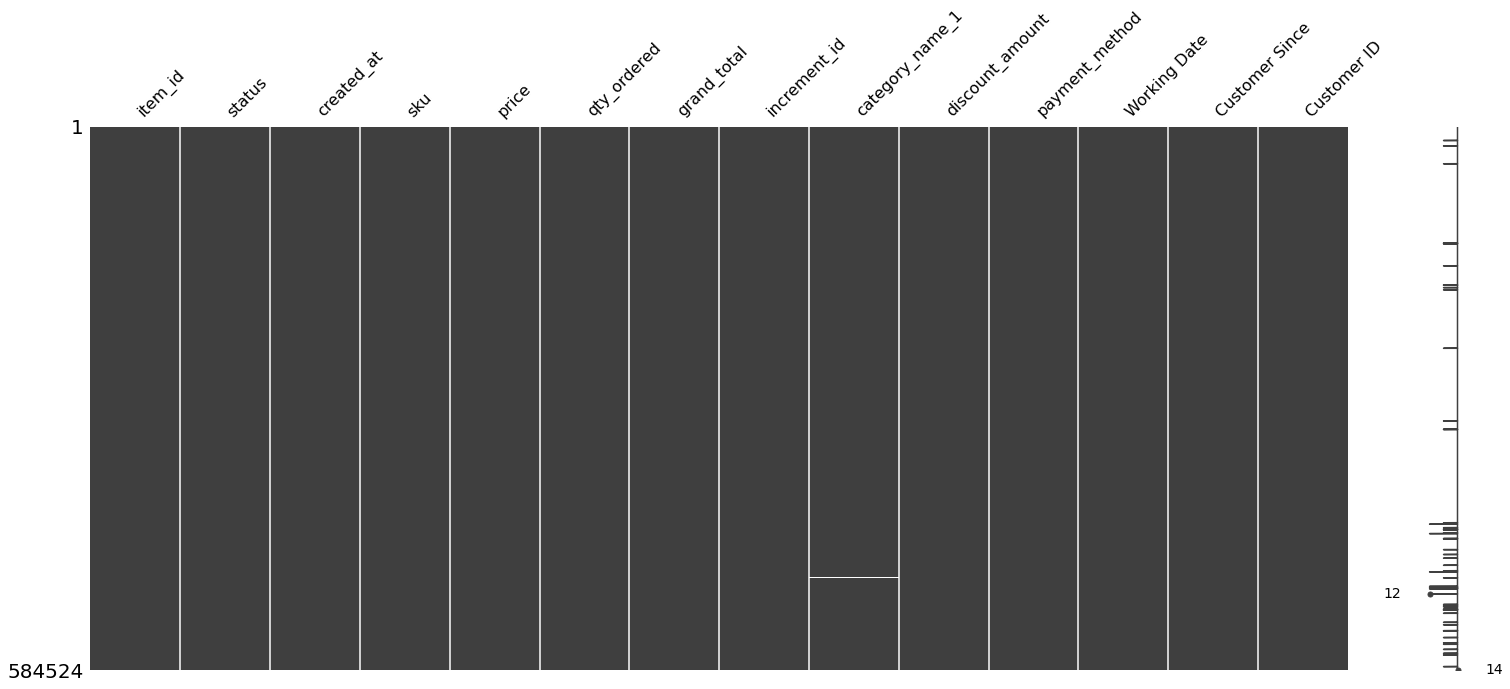
null 값이 있는 것 같습니다.
item_id 0
status 15
created_at 0
sku 20
price 0
qty_ordered 0
grand_total 0
increment_id 0
category_name_1 164
discount_amount 0
payment_method 0
Working Date 0
Customer Since 11
Customer ID 11
dtype: int64Null 값이 그렇게 많지 않으니 그냥 다 삭제하고 진행하겠습니다.
(584314, 14)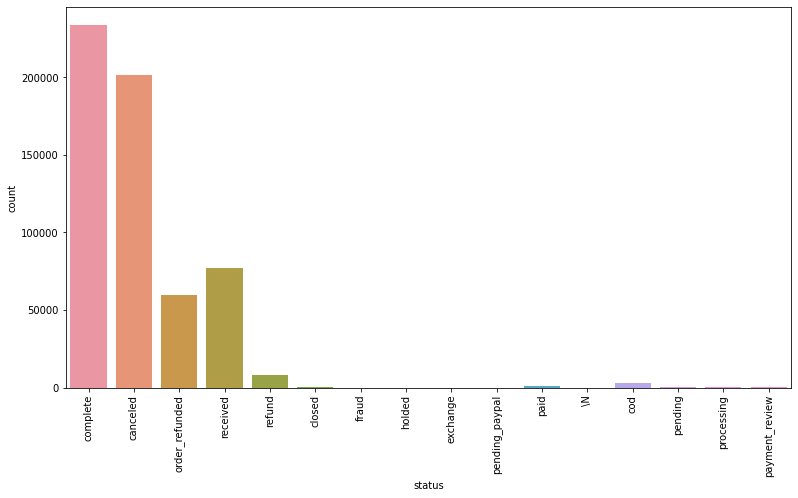
Completed, Canceled, Received, Order_Refunded 및 Refund와 같은 값이 있습니다.
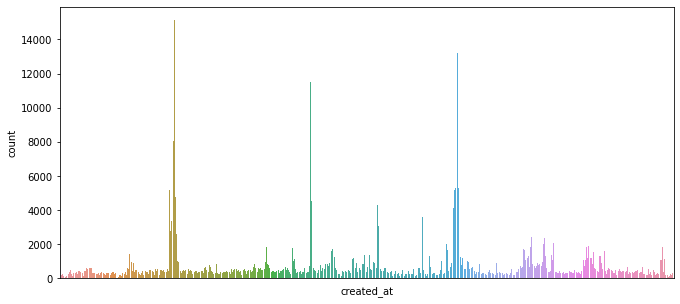
* 이것은 created_at에 대한 그래픽입니다.
* 품목 번호
제품 고유의 가치를 나타냅니다. 총 총 84869개의 상품이 있습니다.
MATSAM59DB75ADB2F80 3775
Al Muhafiz Sohan Halwa Almond 2258
emart_00-7 2027
kcc_krone deal 1894
infinix_Zero 4-Grey 1793
emart_00-1 1391
MATSAM59DB757FB47A2 1273
Rubian_U8 Smart Watch 1233
unilever_Deal-6 1213
APPNAT5A0A01860CE92 1173
Name: sku, dtype: int64상위 10개만 뽑았습니다. 간단한 상품코드로는 어떤 상품이 있는지 알기 어렵지만, 상위 10개 상품에 1,000개 이상의 날짜가 포함되어 있음을 알 수 있습니다.
*가격

매우 높은 제품 3개 정도를 제외하고는 모두 400,000개 이내로 보입니다.
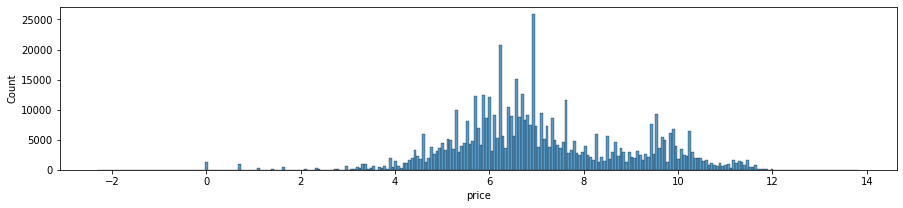
로그 히스토그램을 그리면 대략적으로 정규 분포와 유사한 그래프를 얻을 수 있습니다. 그것은 두 개의 산처럼 약간 모양이 있습니다.
참고로 파키스탄의 화폐단위는 루피이고, 통조림은 280루피 정도인데 우리 돈으로 환산하면 약 1,300원이다. 우리 나라에 비해 가격이 훨씬 저렴합니다. 이 시점에서 데이터 선택에 대해 약간의 후회가 생기기 시작했습니다. 제품명은 아무리 봐도 뭔지 모르겠더라구요. 파키스탄의 공식 언어는 무엇입니까? 영어로 말할 수 있을 것 같지만 매우 걱정됩니다. 당신은 그것을 번역할 수 있습니까? 데이터가 선정되면 최대한 분석을 진행하려고 합니다. 그렇게 한다면 파키스탄의 소비자 문화를 어느 정도 이해할 수 있을 것입니다. 갑시다
총계 값은 다음과 같이 계산됩니다: (price-quantity_ordered)*discount amount. 작동하는지 확인해야합니다.
> 266388강아지만 같이 다니는 듯…
따지고 보면 전체적인 밸런스 자체가 좀 이상하다. 데이터가 너무 깨끗하다고 보기 어려울 수 있습니다. 상태를 살펴보니 연결이 없는 것 같습니다. Kaggle을 보면 이런 문제가 언급되어 있는데 해결하려는 경향이 보이지 않는다.
특히 뒤에는 참 값이 거의 없는 것 같지만, 이것들을 제외하고는 오차가 고루 섞여 있다.

126만 개만 사용하는 두 가지 솔루션을 고려할 수 있습니다. 2. 총계 데이터는 무시하고 사용한다.
여기서 총계는 영수증을 기준으로 합니다. 영수증을 묶었을 때 값이 잘 계산되는지 테스트 해보겠습니다.
약 400,000개의 증거가 있고 그 중 320,000개는 맞지만 약 80,000개는 잘못되었습니다.
환불이나 취소는 따로 처리하는 방법이 있는 것 같습니다. 그러나 그렇지 않더라도 여전히 데이터 무결성 문제가 있습니다.
다른 Kaggle 노트북을 참고했는데 음수 값만 버리고 사용했거나 아예 무시하고 분석을 계속한 것 같다. 지금은 각 행에 대한 개별 합계만 만들고 사용하려고 합니다.
*범주
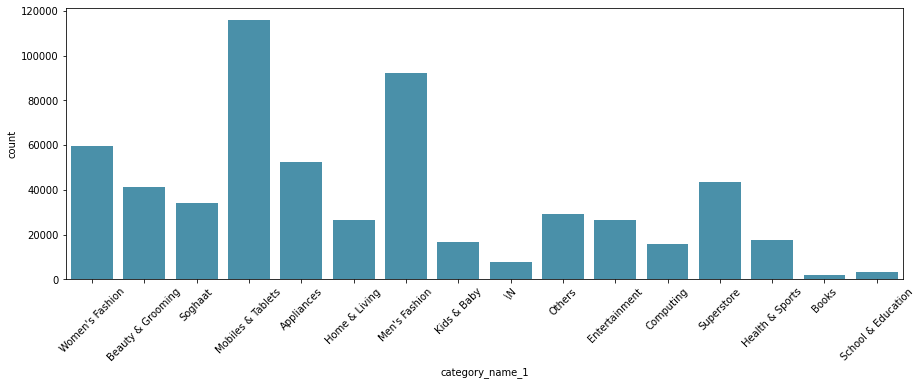
휴대폰과 태블릿이 가장 흔하고 남성복, 남성복, 가전제품이 그 뒤를 잇습니다. Soghaat는 파키스탄의 베이커리 전문점이며 Superstore는 슈퍼마켓의 개념으로 보입니다. /N은 분류되지 않은 경우인 것 같습니다.
*결제방법
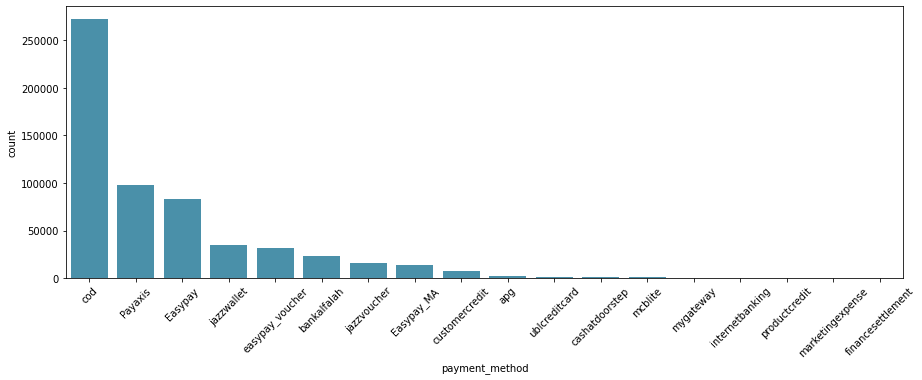
코드는 대금 상환의 한 유형입니다. 상품에 대한 신뢰도가 낮아 상품을 받고 나서 돈을 지불하는 경향이 있기 때문에 이러한 형태의 결제가 주된 결제수단이라고 합니다. 다양한 결제 수단이 만들어진 2023년의 경우는 어떻게 될지 궁금하다. 또한 payaxis, easypay 및 재즈월렛은 모든 유형의 결제 제공업체입니다.
*고객 이후
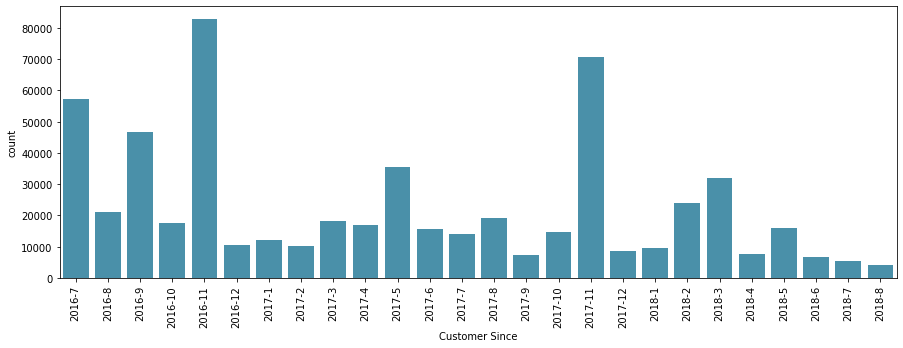
처음 구매한 달의 데이터인 것 같습니다. 어떤 데이터를 근거로 했는지 정확히 알기는 어렵지만 2016년 7월 이전에 매수 데이터가 있었던 것으로 추정되고 있기 때문에 자연스레 근국전선 데이터가 상대적으로 높다고 할 수 있다. 쓸 일이 있을지 모르겠습니다.
* 고객 번호
len(df2('Customer ID').unique())
115304약 110,000명의 고유 고객이 있습니다.
3. 기초분석
kaggle + 개인적인 질문에 대한 데이터 제공자의 질문 중 일부를 해결하고 싶습니다.
- 어떤 카테고리가 가장 잘 팔리나요? (캐글)
- 상태 및 결제 수단 시각화(kaggle)
- cor.(kaggle) 상태 및 지불 방법
- 결제시기 변경
- 주문일 및 카테고리 대응(kaggle)
- 고객 충성도
> 하나씩…
- 어떤 카테고리가 가장 잘 팔리나요? (캐글)
먼저 환불 또는 취소 상태를 삭제하여 판매로 설정하는 것부터 시작하고 싶습니다. (약 310,000로그입니다. 나중에 “구매한” 데이터라고 하겠습니다.)
df_c=df2((df2('status')=='complete')|(df2('status')=='received')|(df2('status')=='cod'))
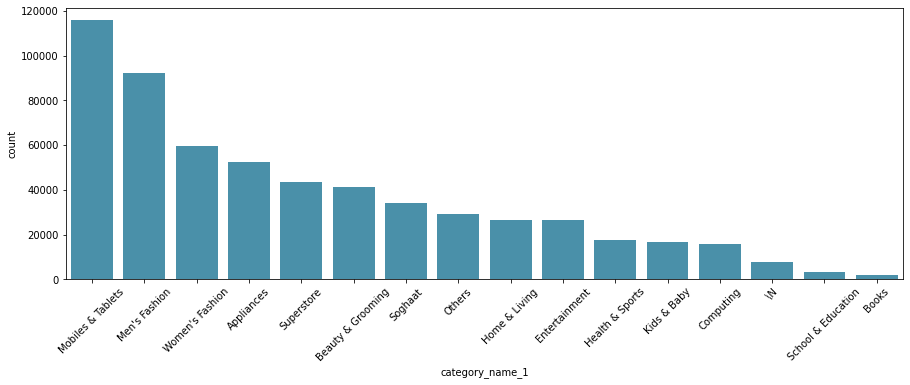
100,000개 이상의 휴대폰과 태블릿, 90,000개 이상의 남성복, 그 뒤를 여성복, 가전제품, 슈퍼마켓 및 뷰티
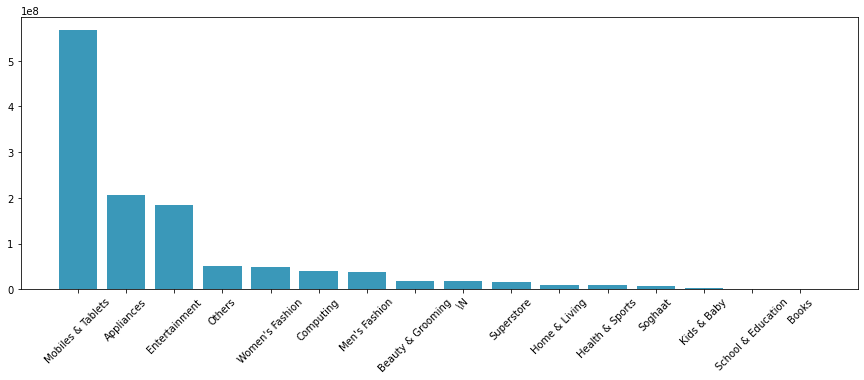
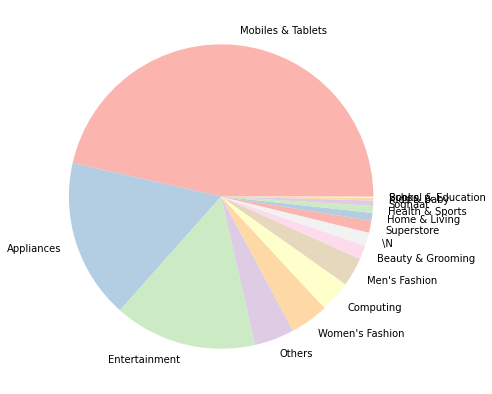
판매량 기준으로 휴대폰 및 태블릿의 총 가치는 약 5억 이상이며, 가전제품 및 엔터테인먼트가 2억 달러, 기타 여성 의류, 컴퓨터 및 남성 의류가 그 뒤를 잇고 있습니다.
제품 수와 가격 면에서 모두 휴대폰과 태블릿이 주요 제품인 것 같습니다. 거의 절반을 차지하는 틈처럼 보입니다. 의류는 구매 건수 면에서 우위를 점하고 있지만, 가치 면에서는 시장점유율이 높지 않다.
엔터테인먼트 산업에 어떤 제품이 포함되어 있는지 살펴 보았고 PlayStation과 같은 것이 있습니다.
- 상태 및 결제 수단 시각화(kaggle)
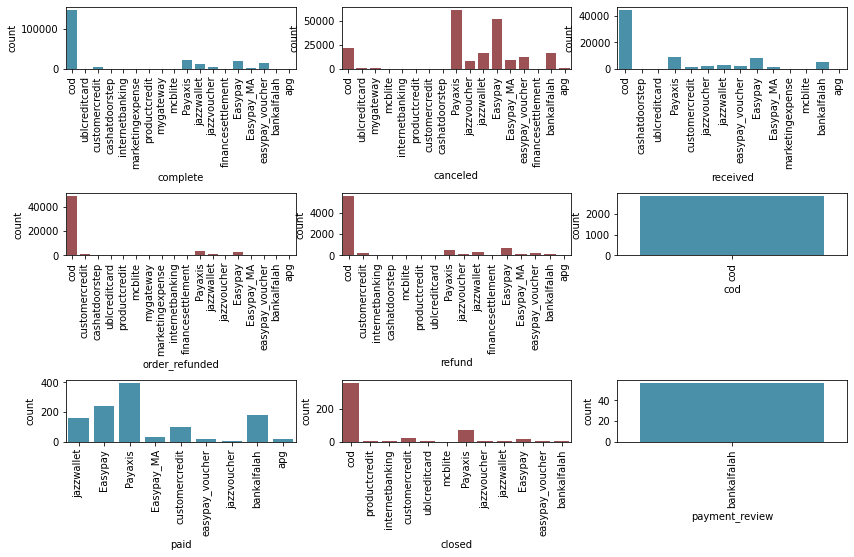
대부분의 결제는 코드로 이루어집니다. 그런데 상태에 별도의 코드가 있는 이유를 모르겠습니다. Payaxis, Easypay 및 Jazzwallet과 같은 다양한 유형의 취소 날짜가 있습니다. 결제에 따라 로그가 조금 다르게 남게 되는 것 같습니다.
- cor.(kaggle) 상태 및 지불 방법
코드 양이 너무 많은 건 아닐까…? Cor를 계산할 때 이것이 의미가 있는지 모르겠습니다. 한 번 일어난다.
- 결제시기 변경
모든 “구매한” 로그 중에서 로그가 10,000개 이상인 결제 유형만 처리되었습니다.
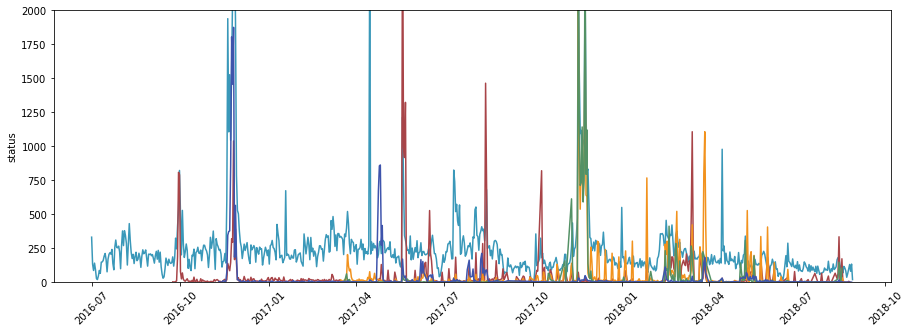
각 범주에는 많은 눈에 띄는 날짜가 있습니다. 전반적으로 코드가 자주 등장하며, 이지페이의 경우 2017년부터 본격적으로 사용되고 있다. 결제 기록 기준이 좀 다른 것 같고 상품 분석을 하면 결제 내역은 생략할 것 같습니다.
- 주문 날짜 및 카테고리에 따라
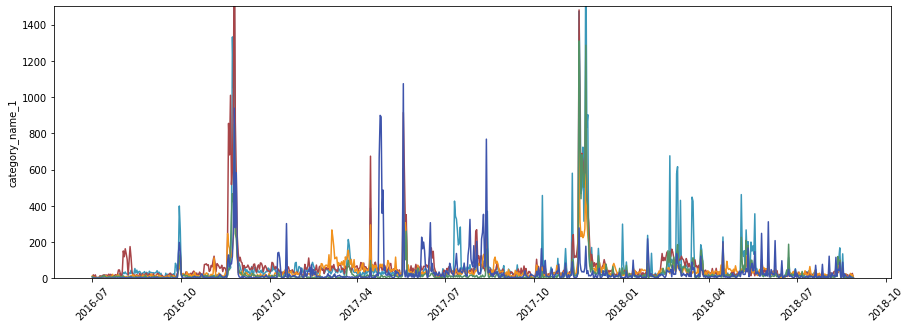
너무 복잡해서 볼 수가 없네요. 월 단위로 분해하고 싶습니다.
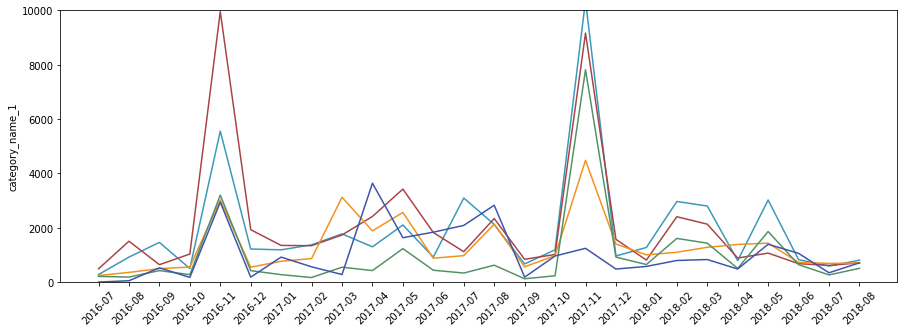
월별로 보면 꽤 깔끔합니다. 동시에 구매가 증가하는 것을 볼 수 있습니다. 음식은 상대적으로 거의 변하지 않는 것으로 보이며 다른 범주가 증가함에 따라 감소하는 경향이 있습니다.
이 기간 동안 구매가 증가한 이유를 파악하려면 조금 더 배경이 필요하다고 생각합니다. 국가가 달라 어느 쇼핑몰에서 통나무를 수집했는지 알기 어렵다. 어쨌든 매수가 일시적으로 반등하는 기간이 있었고 추가 분석이 필요해 보입니다.
- 고객 충성도
len(df_c('Customer ID').unique())
79947구매 이력이 있는 사용자는 약 8만 명…


대부분의 구매는 1에 가깝습니다.
평균은 4이고 중앙값은 2입니다. 그럼에도 불구하고 약 절반의 고객이 하나 이상의 구매 내역을 가지고 있습니다.
군중을 돌아보며

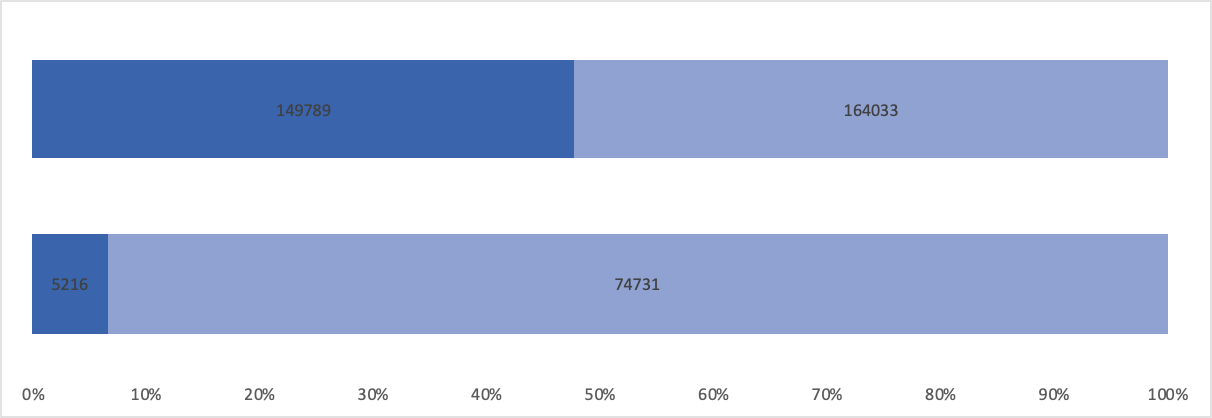
인세를 대략적으로 확인할 수 있는 차트입니다. 10건 이상 구매한 고객은 전체 구매의 10% 미만이지만 거의 절반을 구매합니다.
4. 클러스터 분석
대화 분석에서는 보다 구체적인 군집 분석을 진행하고 이번에는 k-means 군집 분석만 진행하여 쉽게 사용자를 분류하고 마무리하겠습니다.
test=pd.DataFrame(df_c.groupby(('Customer ID', 'category_name_1'))('total').count())
test2=pd.DataFrame(df_c.groupby('Customer ID')('total').count())
test=test.reset_index()
test2=test2.reset_index()
test3=pd.merge(test,test2,on='Customer ID', how='inner')
test3.columns=('Customer ID','category_name_1','cat_total','total')
test3('per')=test3('cat_total')/test3('total')
test3=test3(('Customer ID','category_name_1','per'))
test4=test3.pivot(index='Customer ID', columns="category_name_1", values="per").fillna(0)피벗 형태로 전환되면 클러스터 분석에 사용할 수 있는 형태를 생성합니다.
category_name_1 Appliances Beauty & Grooming Books Computing Entertainment Health & Sports Home & Living Kids & Baby Men's Fashion Mobiles & Tablets Others School & Education Soghaat Superstore Women's Fashion \N
Customer ID
1.0 0.000000 0.000000 0.0 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.0 0.000000 0.000000 1.000000 0.000000
3.0 0.000000 0.000000 0.0 0.000000 0.000000 0.000000 0.000000 0.000000 0.500000 0.500000 0.000000 0.0 0.000000 0.000000 0.000000 0.000000
4.0 0.049242 0.098485 0.0 0.003788 0.037879 0.003788 0.056818 0.015152 0.299242 0.219697 0.003788 0.0 0.113636 0.045455 0.034091 0.018939
6.0 0.000000 0.000000 0.0 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.000000 0.0 1.000000 0.000000 0.000000 0.000000
7.0 0.000000 0.250000 0.0 0.000000 0.000000 0.000000 0.250000 0.000000 0.250000 0.250000 0.000000 0.0 0.000000 0.000000 0.000000 0.000000각 카테고리의 총 구매 횟수는 1회이며 백분율로 환산한 결과를 피벗으로 사용했습니다. 0과 1 사이에 정렬되어 있으므로 표준화하지 않습니다.
분류 기준인 k를 고려하여 엘보우 다이어그램을 그렸습니다.
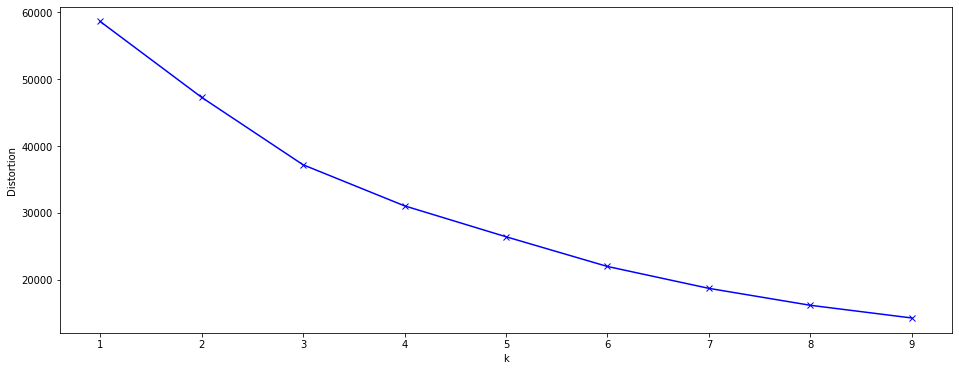
명확한 포인트는 없지만 4/5가 적절할 것 같습니다.
4번과 5번 모두 해봤는데 5번이 분류에 더 적합할 것 같아서 5번으로 분석을 계속했습니다.
test('cluster').value_counts()
1 34995
2 15827
0 15814
3 8316
4 49951에서 약 40 % 이상인 것 같습니다.
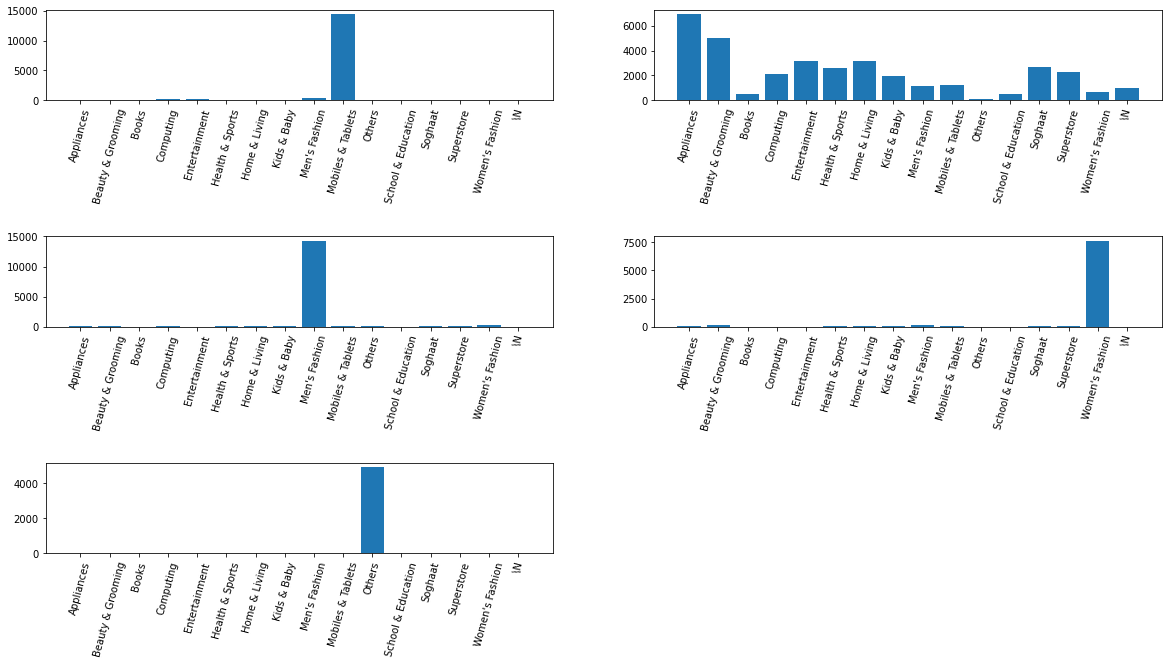
클러스터마다 고유한 범주가 표시됩니다. 예를 들어 휴대폰/태블릿, 남성복, 여성복 등의 카테고리가 구분되어 표시됩니다. 그 외에도 가전제품과 뷰티에 똑같이 초점을 맞춰 다양한 카테고리를 구매하는 그룹이 있고, 주로 다른 제품을 구매하는 그룹이 있습니다.
- 조인 시간과 클러스터 간의 관계
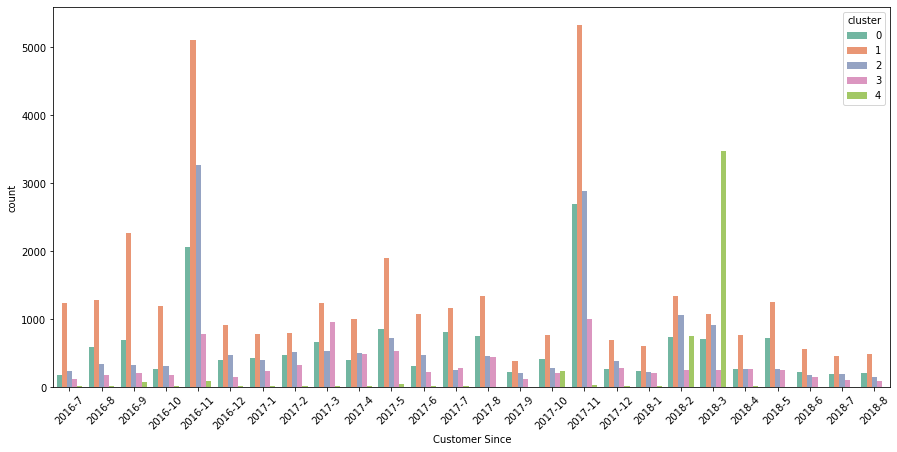
클러스터 0과 1은 2016년 중반부터 사용하고 있는 비교적 많은 사람들입니다. 클러스터 #3은 한때 널리 퍼졌던 2016년 11월 이후로 많은 사람들을 심각하게 만드는 것 같습니다. 4번 클러스터는 2018년경부터 본격적으로 가입한 후 2018년 3월에 가입한 사람들이 많다는 점에서 다소 독특합니다. 다른 사람들은 어떻습니까 그냥 보고 끝내고 싶네요.
별거 아니야. 제품 코드가 너무 많고 다른 검색은 거의 도구와 같았습니다.
소비자에 대한 정보가 많지 않아 구체적인 군집화는 어려웠지만 5개 그룹으로 깔끔하게 묶을 수 있었던 것 같다.
5. 종료
일반적인 구매행태, 임시구매가 증가하는 기간과 종류, 결제수단 등을 고려하였다. 그리고 카테고리 정보를 바탕으로 고객 분류를 위한 군집분석을 수행하였다. 이 데이터에 고객과 관련된 추가 데이터는 많지 않지만 성별이나 연령과 같은 메타 정보를 함께 사용할 수 있다면 고객 확보에 사용할 수 있을 것 같습니다.
이번 분석을 하면서 느낀 점은… 데이터를 고를 때 좀 더 신중하게 선택해야겠다는 생각이 들었습니다. 일단 상품명에 대한 정보가 없어서 정확히 어떤 종류의 구매인지는 확인할 수 없었습니다. 그리고 로그가 어떻게 수집되는지 알 수 없었기 때문에 환불 또는 취소 날짜를 처리하는 방법을 알 수 없었습니다.
계절정보도 생소한 외국이라 이해하기 어려웠고 전자상거래 문화를 이해하는 것이 필요하다고 느꼈습니다. 생소한 데이터를 다룰 때는 조금 더 공부하거나 조금 더 세심하게 분석하는 것이 좋다. 데이터 설명은 미묘하고 오류가 발생하기 쉽습니다.
암튼 전자상거래와 관련된 전반적인 데이터 분석에 만족했습니다. 대화 사례 연구를 하면서 좀 더 복잡한 클러스터 분석을 할 수 있다면 좋을 것 같아요!